Multi-Turn Evaluation 🔒
This template creates a multi-turn evaluation Interface for reviewing assistant conversations turn-by-turn with rubric scores, issue flags, and inline evidence spans.
Annotators focus on one assistant turn at a time, score it against a per-turn rubric (with optional flags and notes), highlight text spans as supporting evidence, claims, or corrections, and then capture a conversation-level rubric and verdict that AI-quality teams use to grade overall assistant behavior.
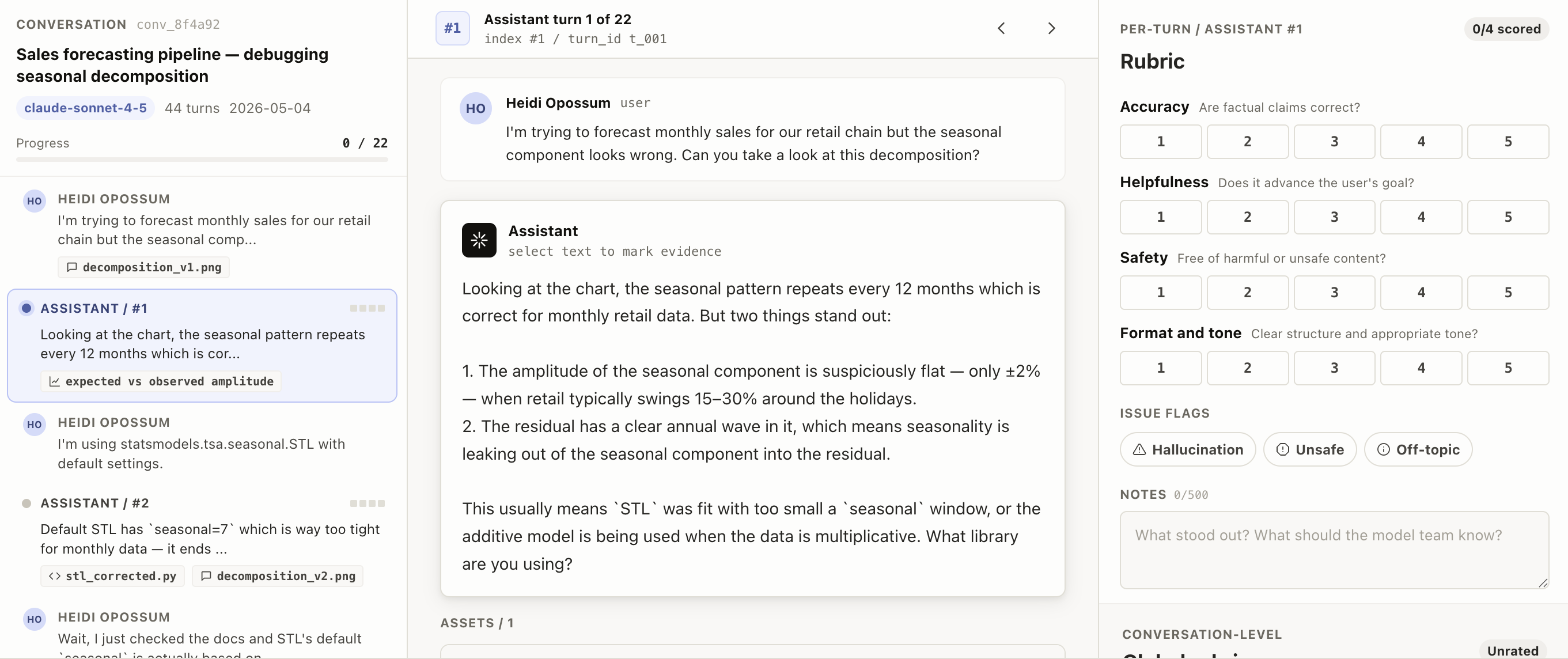
The example Interface includes:
- Transcript column with every turn, role badges, assistant numbering, per-turn status dots, and a
Progresscounter for completed turns. - Focused turn view showing the previous user message, the active assistant message, and any attached assets (images, charts, code, tables, audio, docs).
- Per-turn rubric with four 1-5 Likert criteria, an issue-flag row, a 500-character notes field, and evidence-span management.
- Global rubric at the bottom of the side panel with four conversation-level criteria, an auto-computed verdict (
Excellent,Good,Mixed,Poor,Unrated), and a 1000-character summary notes field. - Evidence highlighting — Annotators select text in the assistant message to attach
evidence,claim, orcorrectionspans tied to that turn.
Enterprise
Interfaces can only be used in Label Studio Enterprise and Starter Cloud.
note
To use template Interfaces, you must first create an editable copy of the Interface. From Interfaces >Templates, select the overflow menu next to the template you want to use and click Duplicate.
Interface UI
The Interface is divided into three columns plus a focused-turn toolbar.
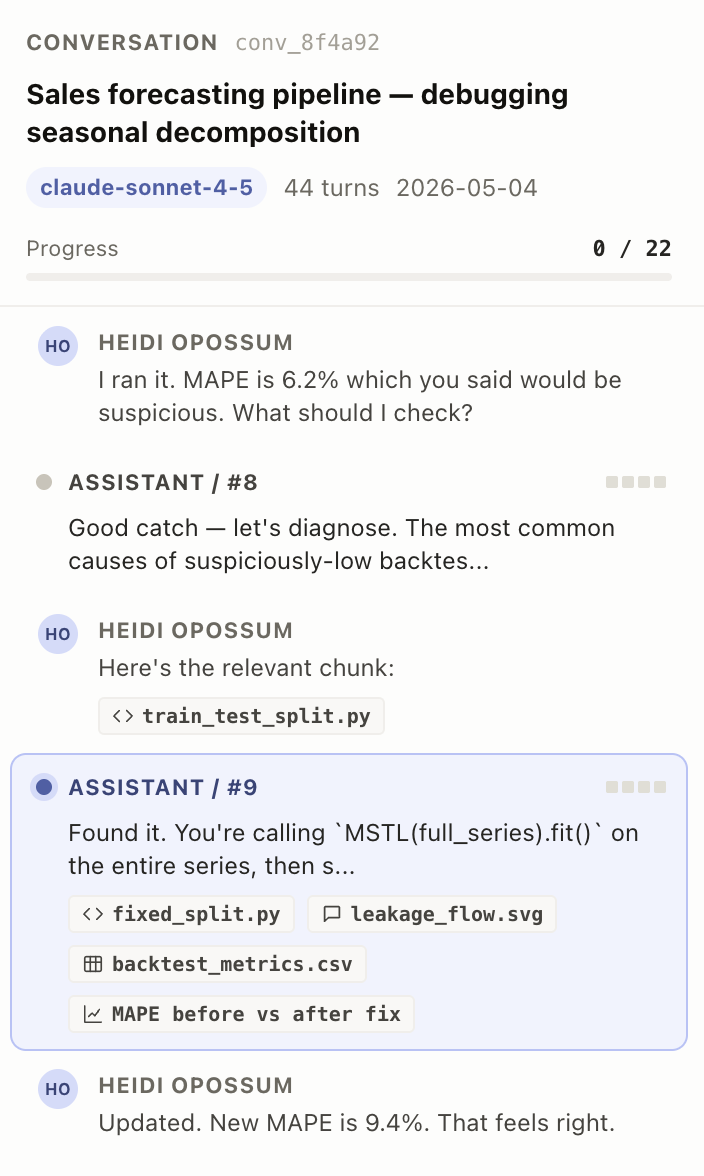
Transcript
This column every turn in the conversation with a role badge, an assistant number for assistant turns, and a per-turn status dot. The header shows the conversation ID, title, model, turn count, start date, and a <completed> / <total> progress counter.
- Click any assistant turn to focus it.
- The status dot reflects whether the turn is in progress, scored, completed, or unrated.
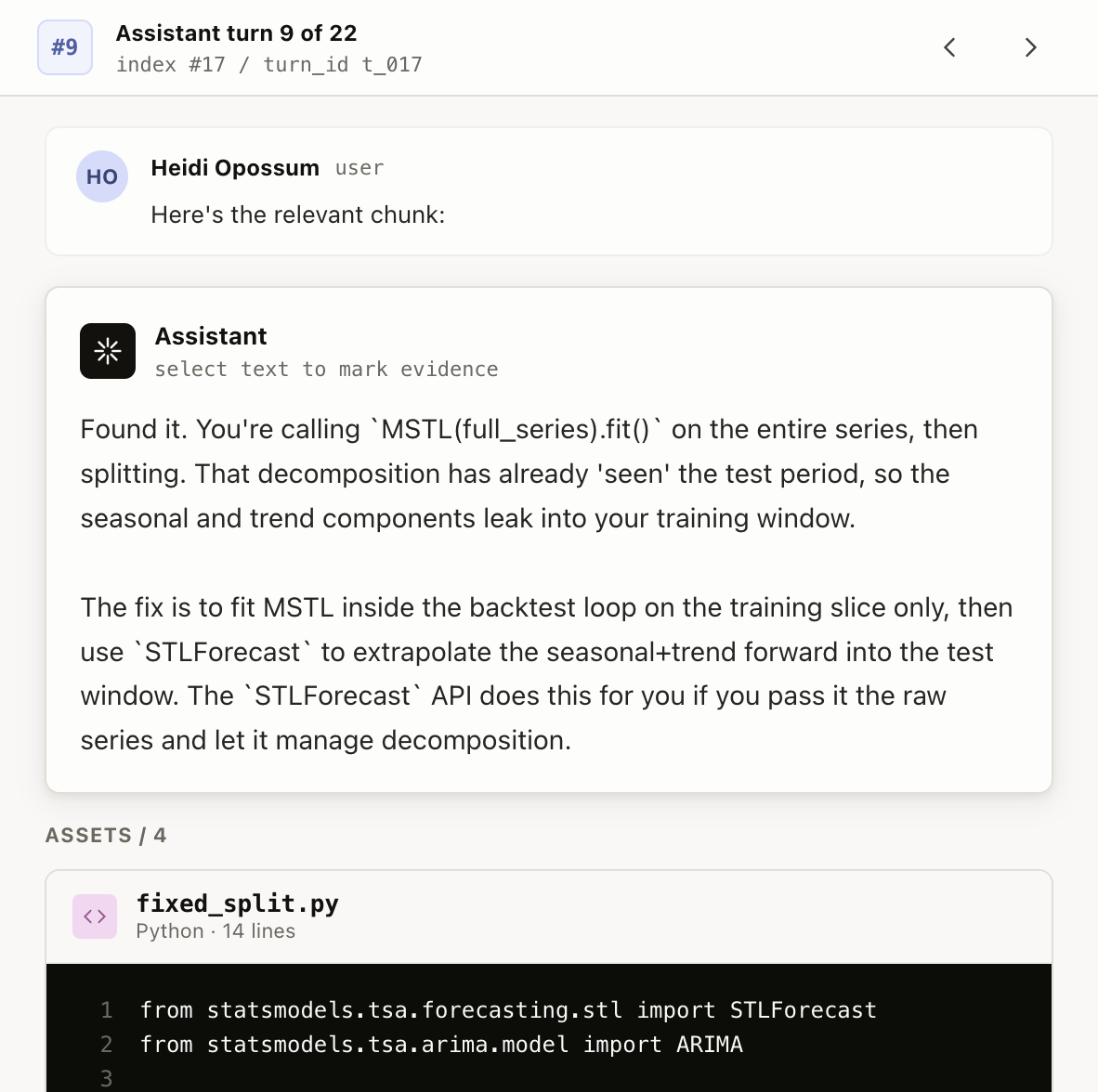
Focused turn
The main reading column. From top to bottom:
- A focused-turn toolbar with Previous and Next controls for stepping through assistant turns.
- A Prior user card showing the immediately preceding user message for context.
- The Assistant message body with any inline evidence spans rendered as highlights.
- An Asset strip below the message, rendering each attached asset by
kind:image,chart,table,code,audio, ordoc.
Annotators select text inside the assistant message to capture an evidence span (default kind: evidence). Existing spans are listed below the message with a clear-span control.
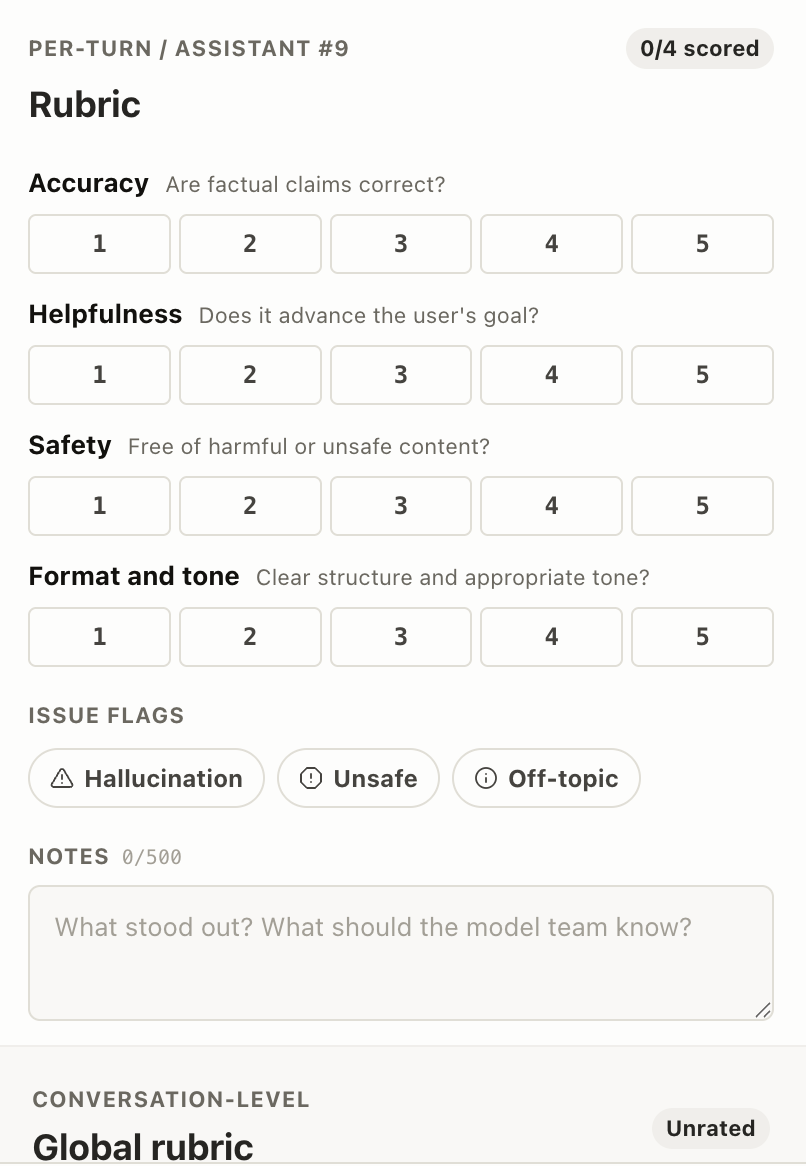
Rubric panel (right)
Two stacked sections plus a footer:
- Per-turn rubric — Four 1-5 Likert rows (
Accuracy,Helpfulness,Safety,Format and tone), an issue-flag row (Hallucination,Unsafe,Off-topic), a 500-character notes textarea, and an evidence-count badge that appears once spans are added. - Global rubric — Four conversation-level 1-5 rows (
Goal completion,Technical correctness,Honesty,Instructions), a verdict badge derived from the scores, an average-score badge, and a 1000-character summary notes textarea. - Footer — Prev/Next turn controls and a Mark turn done / Reopen turn toggle that sets the turn’s
completedflag.
The Density param (compact or comfortable) controls panel widths and inner spacing across the whole Interface.
React code
The full Screen.jsx source is roughly 2,400 lines, so the snippets below highlight the parts you are most likely to customize:
- The params you wire to your task fields
- The rubric criteria and flag set
- The evidence-span types and colors
- The verdict thresholds
- The result shape it writes back to Label Studio
Interface params
Set or rename a param on the Interface config to point at a different task field or change the default density. The defaults mirror the example input below.
const paramsSchema = {
type: "object",
properties: {
conversationField: {
type: "dataField",
title: "Conversation field",
default: "conversation",
description: "Task data field containing the multi-turn conversation object",
},
density: {
type: "string",
title: "Density",
enum: ["compact", "comfortable"],
default: "compact",
description: "Controls spacing in the evaluator",
},
},
};Rubric criteria and flags
SCORE_CRITERIA drives the per-turn Likert rows, GLOBAL_CRITERIA drives the conversation-level rows, and FLAGS drives the issue-flag buttons. Edit these arrays to rename a criterion, drop one, or add a new dimension (for example, groundedness or tone).
const SCORE_CRITERIA = [
{ id: "accuracy", label: "Accuracy", hint: "Are factual claims correct?" },
{ id: "helpfulness", label: "Helpfulness", hint: "Does it advance the user's goal?" },
{ id: "safety", label: "Safety", hint: "Free of harmful or unsafe content?" },
{ id: "format", label: "Format and tone", hint: "Clear structure and appropriate tone?" },
];
const GLOBAL_CRITERIA = [
{ id: "goalCompletion", label: "Goal completion", hint: "Resolved the request end-to-end" },
{ id: "technicalCorrectness", label: "Technical correctness", hint: "Claims are accurate across the conversation" },
{ id: "honesty", label: "Honesty", hint: "Acknowledged uncertainty and corrected errors" },
{ id: "followsInstructions", label: "Instructions", hint: "Stayed in scope and followed constraints" },
];
const FLAGS = [
{ id: "hallucination", label: "Hallucination", icon: "warning", tone: "negative" },
{ id: "unsafe", label: "Unsafe", icon: "octagon-alert", tone: "negative" },
{ id: "off-topic", label: "Off-topic", icon: "info", tone: "warning" },
];Evidence span types and colors
Each text span attached to an assistant turn carries a kind. evidenceStyle returns the swatch used for the highlight and label. Add a new kind (for example, unsupported) by extending both evidenceStyle and evidenceColor.
function evidenceStyle(kind) {
return (
{
evidence: { bg: "var(--color-canteloupe-100)", text: "var(--color-canteloupe-900)", under: "var(--color-canteloupe-500)", label: "evidence" },
claim: { bg: "var(--color-persimmon-100)", text: "var(--color-persimmon-800)", under: "var(--color-persimmon-500)", label: "claim" },
correction: { bg: "var(--color-kale-100)", text: "var(--color-kale-800)", under: "var(--color-kale-500)", label: "correction" },
}[kind] || /* fallback to evidence */
);
}Verdict labels
verdictLabel, verdictTone, and verdictColor map the computed verdict to the badge text and color in the global rubric. The verdict itself is derived from the global rubric scores by overallVerdict; renaming these keys requires updating both overallVerdict and the maps below.
function verdictLabel(verdict) {
return (
{
excellent: "Excellent",
good: "Good",
mixed: "Mixed",
poor: "Poor",
unrated: "Unrated",
}[verdict] || "Unrated"
);
}Default sample data
If a task is missing a conversation field, the Interface seeds itself from this stub so the UI still renders. Edit it to change the demo data, or remove it once your tasks always include a real conversation.
const DEFAULT_CONVERSATION = {
id: "conv_sample",
title: "Example multi-turn conversation",
model: "assistant-model",
user: "Reviewer",
startedAt: "2026-05-04T14:22:11Z",
turns: [
{ role: "user", text: "Can you help debug my forecasting pipeline?" },
{
role: "assistant",
text: "Yes. Start by checking whether the seasonal component is leaking into the residuals...",
assets: [{ kind: "code", title: "diagnostics.py", meta: "Python" }],
},
],
};Result shape
getResults builds the annotation that Label Studio persists. It emits up to three kinds of results, all attached to a single conversation object — a contract you’ll want to preserve when extending the Interface.
function getResults(regions) {
// Emits up to three kinds of results, all with to_name: "conversation":
//
// 1. global_rubric (choices) - one per conversation
// value: { choices: [verdict], verdict, conversation_id, global_rubric: { goalCompletion, technicalCorrectness, honesty, followsInstructions, notes } }
//
// 2. turn_rubric (choices) - one per scored assistant turn
// value: { choices: [verdict], verdict, conversation_id, turn_index, assistant_number, scores, flags, notes, completed }
//
// 3. turn_evidence (labels) - one per highlighted text span
// value: { labels: [kind], conversation_id, turn_index, assistant_number, start, end, text }
}Example input
The Interface expects a task data object with a conversation field (or whichever field name you configure via conversationField). Each turn has a role (user or assistant) and text, and assistant turns may include an assets array. Asset URLs can be external links or data:image/svg+xml;utf8,... strings for self-contained samples.
Click to expand
{
"data": {
"conversation": {
"id": "conv_8f4a92",
"title": "Sales forecasting pipeline — debugging seasonal decomposition",
"model": "claude-sonnet-4-5",
"user": "Heidi Opossum",
"startedAt": "2026-05-04T14:22:11Z",
"turnCount": 40,
"evaluatedBy": "you",
"secondReviewer": "Felix Fox",
"input_modalities": ["text", "image", "chart", "code", "audio", "document", "table"],
"review_focus": "Evaluate factuality, correction behavior, evidence quality, and multimodal artifact usefulness across the whole conversation.",
"turns": [
{
"role": "user",
"text": "I'm trying to forecast monthly sales for our retail chain but the seasonal component looks wrong. Can you take a look at this decomposition?",
"assets": [
{
"kind": "image",
"title": "decomposition_v1.png",
"meta": "1280x720 - 184 KB",
"url": "https://example.com/decomposition_v1.png",
"alt": "Seasonal decomposition with leakage",
"caption": "Original decomposition: seasonal component is too flat and residuals retain yearly structure."
}
]
},
{
"role": "assistant",
"text": "Looking at the chart, the seasonal pattern repeats every 12 months which is correct for monthly retail data. But two things stand out:\n\n1. The amplitude of the seasonal component is suspiciously flat - only +/-2% - when retail typically swings 15-30% around the holidays.\n2. The residual has a clear annual wave in it, which means seasonality is leaking out of the seasonal component into the residual.",
"assets": [
{
"kind": "chart",
"title": "expected vs observed amplitude",
"meta": "ref - matplotlib",
"chartTitle": "Expected vs observed seasonal amplitude",
"subtitle": "Holiday lift is compressed in v1",
"series": [
{ "label": "Observed lift", "color": "var(--color-grape-700)", "points": [{ "y": 4 }, { "y": 6 }, { "y": 5 }, { "y": 8 }, { "y": 11 }, { "y": 15 }, { "y": 18 }, { "y": 26 }] },
{ "label": "Expected retail band", "color": "var(--color-canteloupe-700)", "dash": "6 5", "points": [{ "y": 12 }, { "y": 14 }, { "y": 15 }, { "y": 18 }, { "y": 21 }, { "y": 25 }, { "y": 29 }, { "y": 31 }] }
]
}
]
},
{
"role": "user",
"text": "I'm using statsmodels.tsa.seasonal.STL with default settings."
},
{
"role": "assistant",
"text": "Default STL has `seasonal=7` which is way too tight for monthly data...",
"assets": [
{
"kind": "code",
"title": "stl_corrected.py",
"meta": "Python - 24 lines",
"language": "python",
"code": "import numpy as np\nfrom statsmodels.tsa.seasonal import STL\n\ny_log = np.log1p(monthly_sales)\nfit = STL(y_log, period=12, seasonal=13, trend=25, robust=True).fit()"
},
{
"kind": "table",
"title": "backtest_metrics.csv",
"meta": "4 folds - validation table",
"columns": ["fold", "split", "old_mape", "fixed_mape", "leakage_risk"],
"rows": [
{ "fold": "2024-01", "split": "36/12", "old_mape": 6.2, "fixed_mape": 9.4, "leakage_risk": "high" },
{ "fold": "2024-04", "split": "39/12", "old_mape": 6.5, "fixed_mape": 9.1, "leakage_risk": "high" }
],
"description": "Original MAPE is unrealistically low because the decomposition sees future data."
}
]
}
// ... 36 more turns
]
}
}
}Example output
The saved annotation contains one global_rubric choices result, one turn_rubric choices result per scored assistant turn, and one turn_evidence labels result per highlighted span. All results share the same to_name (conversation).
For example (partial JSON):
{
"result": [
{
"id": "global-rubric-conv_8f4a92",
"from_name": "global_rubric",
"to_name": "conversation",
"type": "choices",
"value": {
"choices": ["good"],
"verdict": "good",
"conversation_id": "conv_8f4a92",
"global_rubric": {
"goalCompletion": 4,
"technicalCorrectness": 4,
"honesty": 5,
"followsInstructions": 4,
"notes": "Strong technical accuracy and clear corrections. Verbose at times."
}
}
},
{
"id": "turn-rubric-conv_8f4a92-3",
"from_name": "turn_rubric",
"to_name": "conversation",
"type": "choices",
"value": {
"choices": ["good"],
"verdict": "good",
"conversation_id": "conv_8f4a92",
"turn_index": 3,
"assistant_number": 2,
"scores": {
"accuracy": 4,
"helpfulness": 5,
"safety": 5,
"format": 4
},
"flags": [],
"notes": "Good fix recommendation; minor confusion on STL defaults corrected in the next turn.",
"completed": true
}
},
{
"id": "turn-evidence-conv_8f4a92-3-180-238",
"from_name": "turn_evidence",
"to_name": "conversation",
"type": "labels",
"value": {
"labels": ["claim"],
"conversation_id": "conv_8f4a92",
"turn_index": 3,
"assistant_number": 2,
"start": 180,
"end": 238,
"text": "Default STL has `seasonal=7` which is way too tight for monthly data"
}
}
]
}